
September 11, 2025
Paper-club sessions: LIMO: Less is More for Reasoning
AI reasoning may not need huge datasets: LIMO shows complex math skills can emerge with few examples, challenging old assumptions.
![[Paper-club sessions] LIMO: Less is More for Reasoning](https://cdn.prod.website-files.com/6654b3697a9d140e0ca14e14/68c29fab9171604aaae334a4_ChatGPT%20Image%2011%20de%20set.%20de%202025.png)
The field of AI research has long held the assumption that complex reasoning tasks require massive amounts of training data to achieve competence. In the paper "LIMO: Less is More for Reasoning" [1], researchers Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu from SJTU, SII, and GAIR challenge this fundamental assumption with a striking discovery. Their work demonstrates that sophisticated mathematical reasoning capabilities in large language models can be effectively elicited with surprisingly few examples, turning conventional wisdom on its head and suggesting a paradigm shift in how we understand the emergence of complex cognitive abilities in AI systems.
The current approach to developing reasoning capabilities in large language models typically involves supervised fine-tuning on massive datasets, often exceeding 100,000 examples. This practice stems from two widespread assumptions: first, that mastering complex cognitive processes requires extensive supervised demonstrations, and second, that supervised fine-tuning leads primarily to memorization rather than true generalization. Previous work has shown some success with this approach, but at substantial computational cost and data collection burden. Meanwhile, recent advances have fundamentally transformed how LLMs acquire, organize, and utilize reasoning knowledge, with modern foundation models now incorporating unprecedented amounts of mathematical content during pre-training and new techniques allowing for longer reasoning chains at inference time.
LIMO challenges the status quo by demonstrating that with merely 817 carefully curated training samples, models can achieve 57.1% accuracy on the highly challenging AIME benchmark and 94.8% on MATH, dramatically outperforming previous SFT-based models that achieved only 6.5% on AIME and 59.2% on MATH while using 100 times more training data. As illustrated in Figure 1, this represents a remarkable 778% performance gain on AIME while using just 1% of the training data. The authors propose the Less-Is-More Reasoning Hypothesis, which posits that when domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning capabilities can emerge through minimal but precisely orchestrated demonstrations of cognitive processes. The key innovation lies not in scaling data but in the quality of reasoning chains that make the cognitive process explicit and traceable, functioning as "cognitive templates" that show the model how to effectively utilize its existing knowledge base.
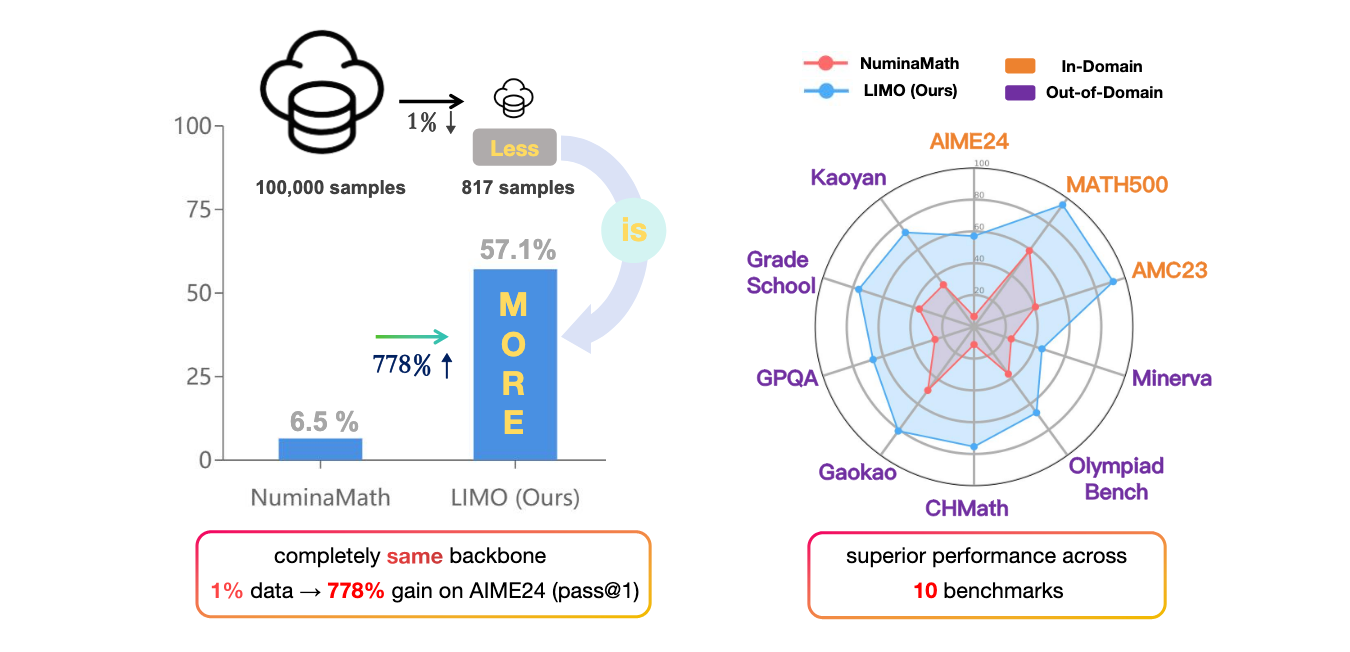
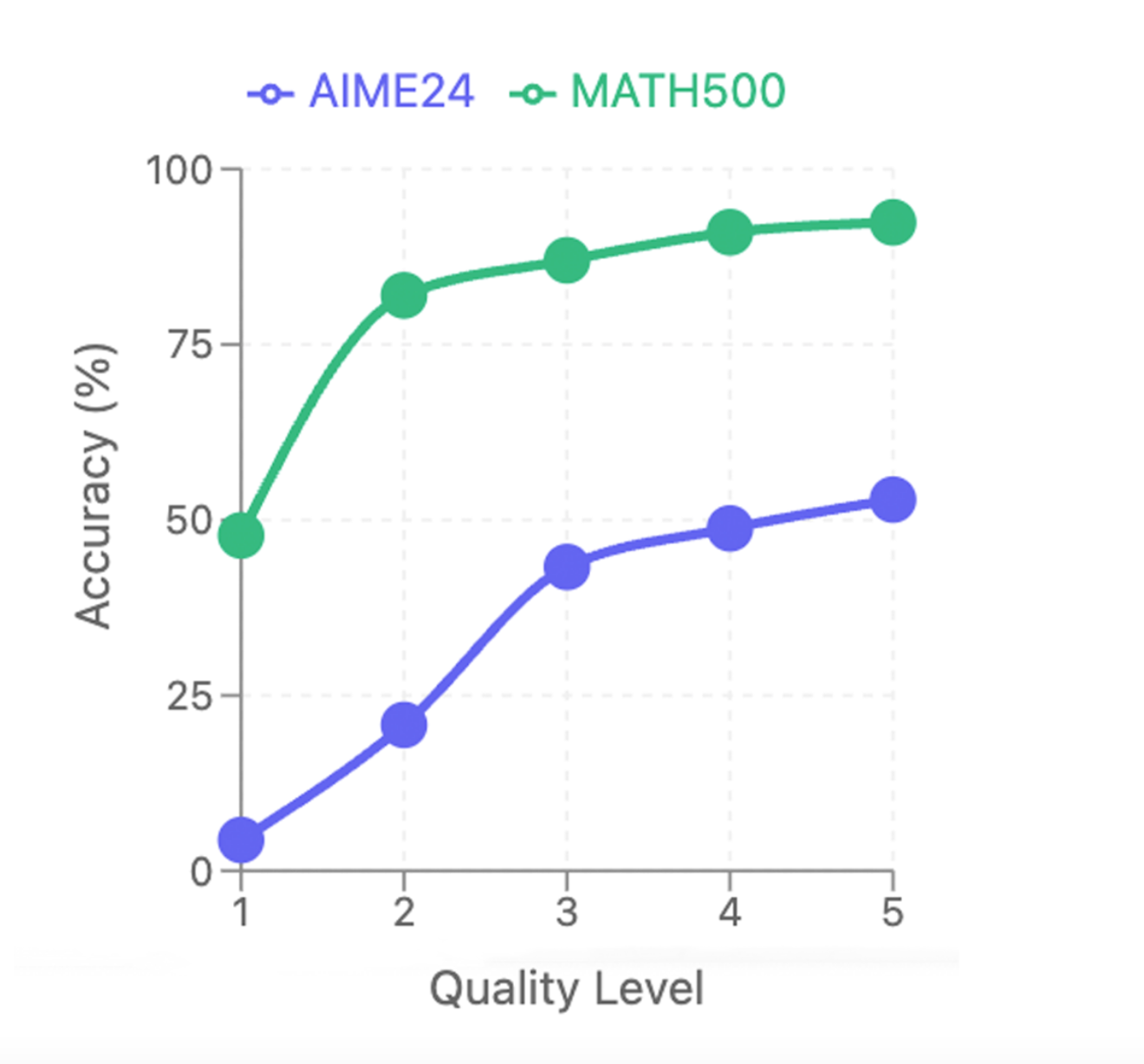
The experimental results reveal that LIMO not only excels at in-domain tasks but also demonstrates exceptional out-of-distribution generalization, achieving a 40.5% absolute improvement across 10 diverse benchmarks compared to models trained on 100 times more data. This strong generalization capacity directly challenges the prevailing notion that supervised fine-tuning inherently leads to memorization rather than genuine reasoning. The authors conducted rigorous comparative analyses to understand what factors contribute to LIMO's success, finding that reasoning chain quality and problem difficulty significantly impact performance. Figure 2 clearly demonstrates the crucial importance of reasoning chain quality, showing a direct correlation between the quality level of training examples and model performance on both AIME24 and MATH500. High-quality reasoning chains are characterized by clear structural organization, effective cognitive scaffolding, and frequent verification steps, providing empirical evidence for why LIMO outperforms models trained on much larger datasets.
This pioneering work has profound implications for artificial intelligence research and development. It suggests that even competition-level complex reasoning abilities can be effectively elicited through minimal but high-quality examples given sufficient domain knowledge and computational space for reasoning. The LIMO hypothesis identifies two critical factors that determine the elicitation threshold for complex reasoning: the completeness of the model's encoded knowledge foundation during pre-training and the effectiveness of post-training examples in demonstrating systematic problem-solving processes. This represents not merely an argument for data efficiency but a fundamental insight into how complex reasoning capabilities emerge in large language models. To facilitate reproducibility and future research in data-efficient reasoning, the authors have released LIMO as a comprehensive open-source suite, providing valuable resources for the AI community to build upon this promising direction.
Final remarks
The LIMO approach underscores that data-driven methods remain crucial for unlocking the full potential of large language models. However, it shifts the conversation away from simply increasing the volume of data to enhancing its quality. Academic research, therefore, should prioritize designing and refining high-quality, step-by-step “cognitive templates”—much like how a teacher carefully explains each step of a problem to a child. Historically, the assumption was that more data inevitably leads to better performance in LLMs. LIMO challenges this by suggesting there may be a “perfect point” or optimal data threshold—beyond which additional examples can introduce noise, redundancy, and diminished returns.
Consequently, the future likely involves a human-in-the-loop process, where domain experts meticulously craft these cognitive scaffolds. In doing so, they will guide AI systems more efficiently, leading to faster breakthroughs in both research and real-world problem-solving. There could also be research on agentic algorithms that could create these optimal steps but introducing diversity in these steps would be a crucial task .
By emphasizing quality over quantity, LIMO paves the way for more sustainable, interpretable, and efficient AI systems. Future work will likely explore how to automate this process, integrate it with domain expertise in real-world applications, and address broader ethical and societal impacts. The combination of human craftsmanship in designing “cognitive templates” and adaptive AI that learns and refines these templates could be the key to unlocking the next wave of breakthrough innovations in large language models.
References
[1] Ye, Y., Huang, Z., Xiao, Y., Chern, E., Xia, S. and Liu, P., 2025. LIMO: Less is More for Reasoning. arXiv preprint arXiv:2502.03387. Available at: https://arxiv.org/pdf/2502.03387


Explore our content
Get to know and learn more about Cloudwalk below.


.png)
