
September 22, 2025
RAG, Tool-Calling, and the Fight Against Hallucinations
This article serves as a survey and futuristic perspective on trustworthy AI anchored on knowledge retrieval
Large Language Models (LLMs), trained on massive text corpora, inherently encode a surprising amount of factual knowledge in a complex geometry. With carefully designed prompts, they can recall information about history, science, culture, and beyond. However, unlike a structured database, this knowledge is diffusely embedded and distributed across billions of parameters by training subject to compression losses (Bricken et al., 2023; Chlon et al., 2025), making fact retrieval probabilistic and vulnerable to hallucinations. This article serves as a survey and futuristic perspective on trustworthy AI anchored on knowledge retrieval.
To address these challenges, several directions have been explored: probing pre-trained models for factual content, enhancing them with Retrieval-Augmented Generation (RAG) or tool integration, and benchmarking factual consistency. Complementary approaches such as fine-tuning and new uncertainty measures (e.g., semantic entropy) seek to improve trustworthiness and adapt models to specific domains. In terms of training innovations, prompting strategies like Chain-of-Thought and Tree-of-Thought have been applied to enhance reasoning and factual recall. Meanwhile, efforts to reduce hallucination at the training level include architectural refinements and new objectives such as sharpened softmax functions and factuality-aware training losses. At the same time, critics—most prominently Yann LeCun—argue that autoregressive LLMs are structurally constrained, sparking debate about whether current architectures can truly scale into reliable reasoning systems.
Retrieval-Augmented Generation (RAG)
In 2020 Lewis et al. introduced the Retrieval-Augmented Generation (RAG) based on Parametric memory: the large pretrained language model (LM), which encodes general world knowledge in its weights. Non-parametric memory: an external retrieval system (e.g., a dense vector index of Wikipedia passages). Retrieve: Given a query (like a user prompt), the retriever finds relevant passages from a large corpus, in more technical terms this means calculating the cosine similarity between content and query; Augment: These retrieved passages are fed into the generator along with the query; Generate: The LM then produces an answer conditioned on both the query and the retrieved evidence.
In the LLM-era RAG: Generator is a huge foundation model (GPT-3, LLaMA, Mistral, etc.) with billions of parameters. This makes the generator far more capable, but also more prone to hallucination if not grounded. LLM RAG is usually non-parametric augmentation without fine-tuning (Ram et al., 2023; Ma et al., 2023): The LLM is frozen (API or open-weights); Only embeddings are trained/fine-tuned (sometimes not even that — off-the-shelf sentence transformers are used). However, traditional RAG systems always retrieve a fixed number of documents for generation, regardless of whether retrieval is actually necessary and also they never reassess the quality of the generated output.

Therefore, more advanced methods began to emerge—too many to cover in detail here. SELF-RAG (Asai et al., 2023) trains an LLM to (1) decide when to retrieve external documents, (2) generate an answer, and (3) critique its own work—segment by segment—using special “reflection tokens.” Graph RAG (He et al., 2024; Edge et al., 2025) structures the corpus as a knowledge graph so retrieval can target entities, relations, and multi-hop subgraphs, enabling both local and global context aggregation. Agentic RAG (Chen et al., 2025) reframes the pipeline as a cooperative multi-agent system—e.g., planner, retriever, reasoner, critic—coordinated via multi-agent reinforcement learning around a shared reward to produce more aligned, effective outputs. Despite the advance of more recent and powerful methods the costs involved and latency need to be taken into account, once some solutions are computationally intensive and can consume a large amount of tokens and other resources, even evolving training.
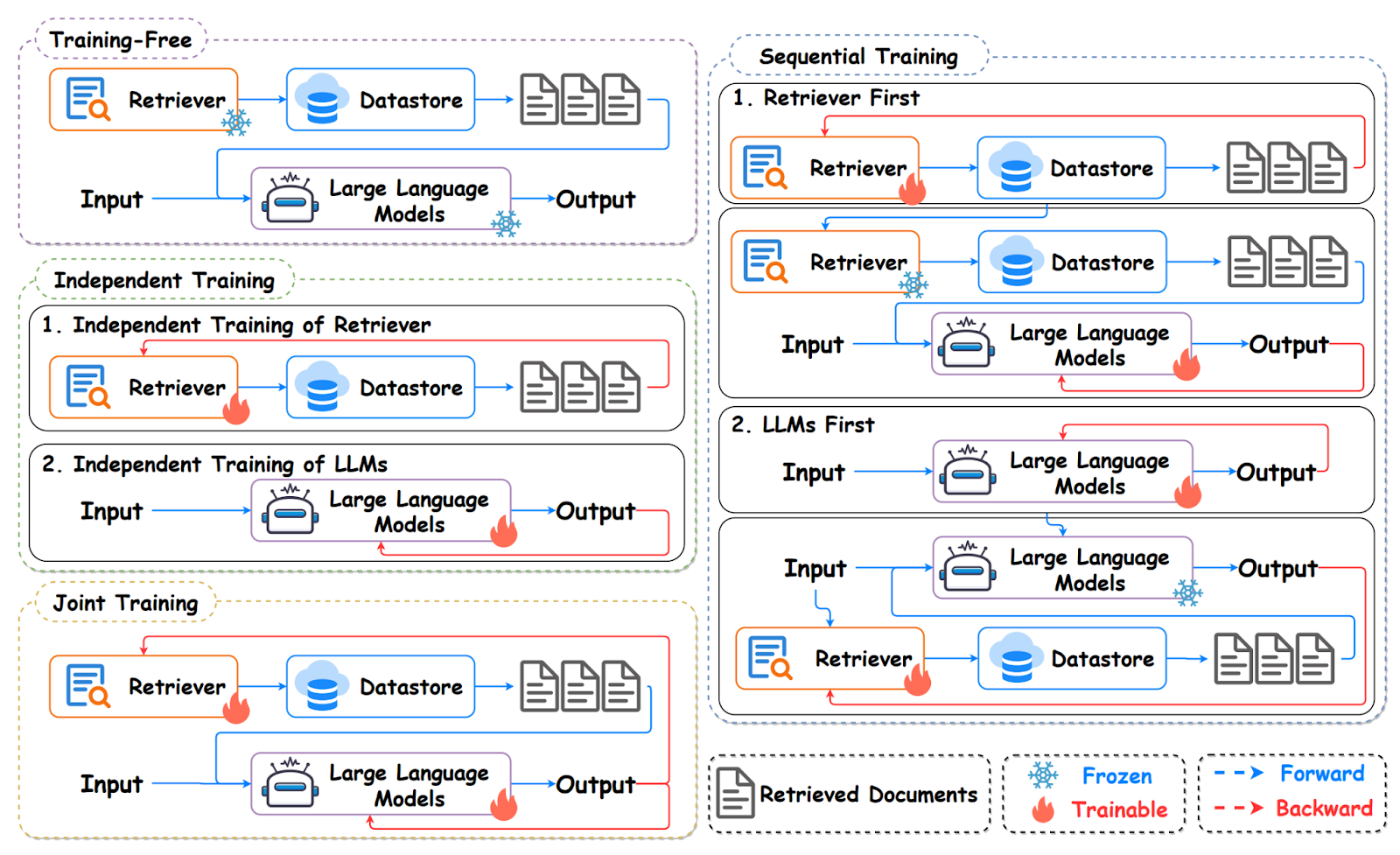
Tool Calling and RAG
An alternative to RAG was thought to be tool calling, where an LLM invokes specialized APIs instead of retrieving documents. For example, instead of searching a knowledge base, the model can call a weather API, a database query function, or a calculator for example anthropic-retrieval. Tool calling emphasizes precision and functionality rather than retrieval breadth. While RAG enhances factual grounding with text evidence, tool calling empowers LLMs to perform real-world actions, integrate with structured data, and dynamically extend their capabilities. However, the sweet spot is in between, in practice, many systems blend RAG and tool calling—retrieving documents when unstructured context is needed, and invoking APIs for structured or dynamic facts using; Orchestration frameworks (LangChain, LlamaIndex, Haystack) control the retrieval–generation loop.
Reliability Benchmarks
To measure factual reliability, there are several benchmarks such as TruthfulQA, FactScore, SciQ, MMLU, and HaluEval. These aim to evaluate whether models can distinguish fact from fiction, resist adversarial prompts, and provide calibrated answers. Benchmarks highlight weaknesses in LLMs’ factual reasoning—such as confidently asserting falsehoods or failing on domain-specific knowledge. However, benchmarks themselves can be limiting, as they often measure static performance rather than robustness in dynamic real-world contexts, and induce a guess behavior to increase performance, which will be discussed further in this article (Fan et al., 2025).
Fine-Tuning
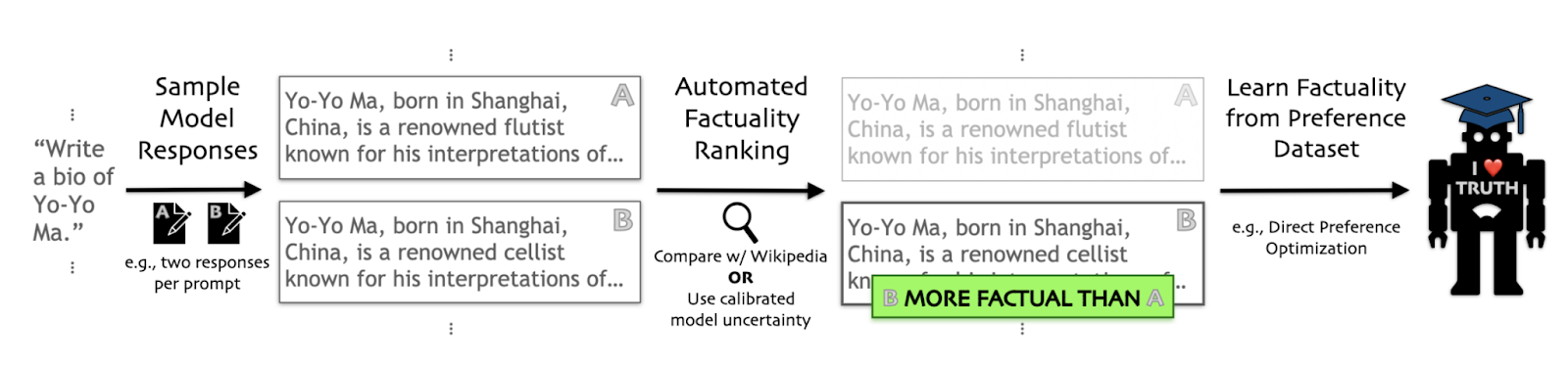
Pre-trained models are usually fine-tuned for reliability; however, it's clear by now that this is not enough. Thus, additional fine tuning steps can be included to make LLMs more factual, for example, Tian et al., 2024 method learned from automatically generated factuality preference rankings—via retrieval-based or retrieval-free methods—greatly improving Llama-2’s accuracy on unseen topics. At 7B scale, this approach cuts factual error rates by 53% in biographies and 50% in medical Q&A, outperforming RLHF and decoding-based strategies.
In addition to the methods already discussed, results can often be also improved further by fine-tuning the retrieval mechanism, for example embeddings. This typically begins with constructing a dataset that defines what “similarity” means in your specific context. Such datasets are commonly organized as triplets: (anchor, positive, negative).
Anchor: The original query or sentence.
Positive: A sentence that is semantically very similar—or even identical—to the anchor.
Negative: A sentence related to the topic but semantically distinct.
Entropy as a detection tool
Semantic entropy is a proposed method to quantify uncertainty in LLM outputs. Unlike classic entropy (which measures uncertainty in the probability distribution over tokens), semantic entropy evaluates meaning-level uncertainty by clustering multiple sampled outputs into semantically distinct groups. If many diverse meanings arise, entropy is high; if outputs converge on a single interpretation, entropy is low. This is crucial for safety and reliability: a model might generate fluent text with low token entropy, yet still have multiple plausible but conflicting semantic interpretations. Measuring semantic entropy, which differs from naive entropy, offers a better lens into when models are likely to be factually unreliable (Farquhar et al., 2025).
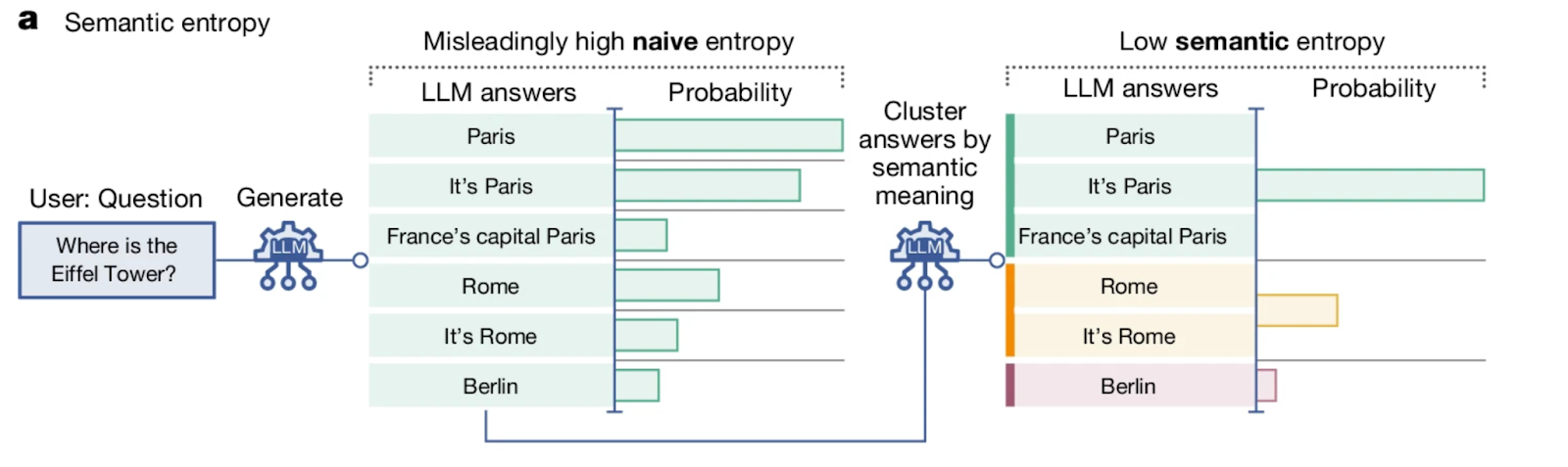
But why do LLMs hallucinate?
As summarized by Sun et al., 2025, hallucinations often arise when models lean on memorized facts (parametric knowledge bias) and spurious correlations, take shortcuts, and express over-confidence; popular facts overshadow rare ones (knowledge shadowing) and long-tailed, low-frequency entities suffer. During generation, exposure bias lets early errors compound (Udandarao et al., 2024) and decoding randomness can push outputs down a wrong path. Gaps or sparsity in training data and out-of-distribution prompts further nudge the model to choose the strongest association rather than the correct answer.
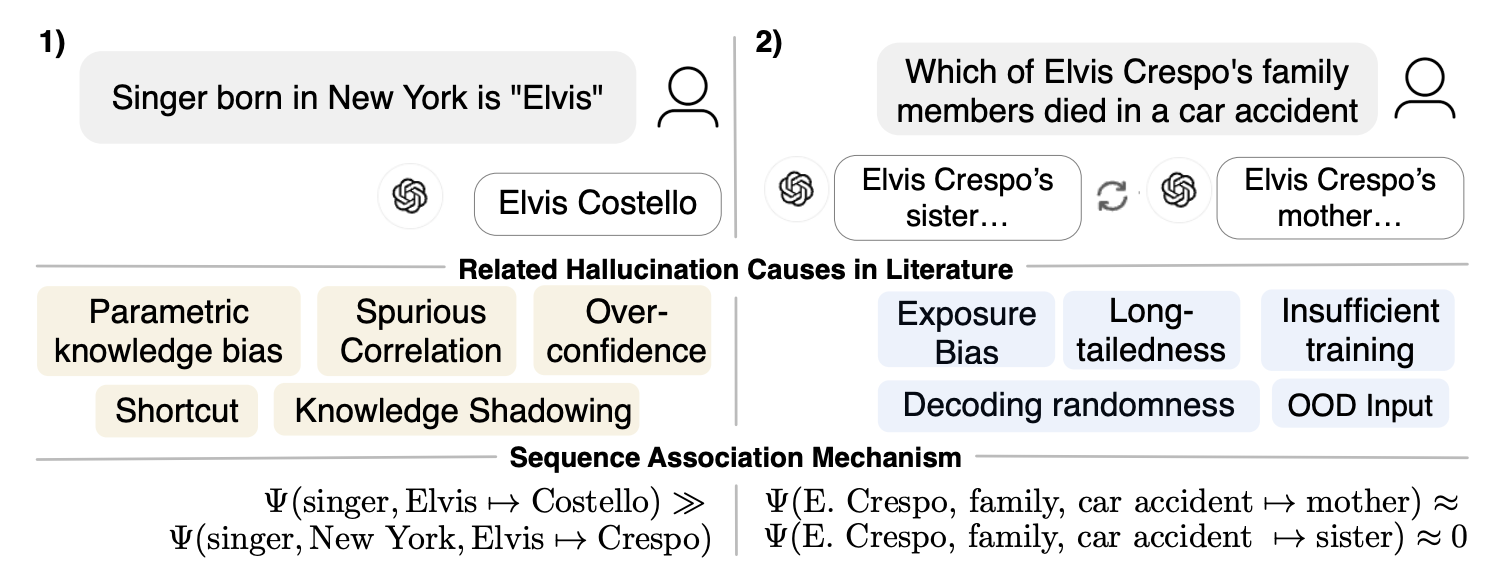
In OpenAI’s paper, Fan et al. (2025) goes deeper and argues that LLM “hallucinations” are expected by products of pretraining: generative errors mirror supervised misclassifications from cross-entropy minimization. They also claim that mainstream evaluations incentivize hallucination; small tweaks that reward calibrated uncertainty instead can realign incentives and ease hallucination suppression. Thus, LLMs are being optimized to do well on tests, so when they’re unsure, guessing often helps them score better. Many benchmarks mirror standardized exams and use binary scores like accuracy or pass rate, optimizing for them can inadvertently encourage hallucinations. This way, they propose a change in the way we optimize the models to a setting that rewards differently with other benchmarks.
Yann LeCun’s Unpopular Opinion about Autoregressive LLMs
Yann LeCun, Turing Award winner and Meta’s Chief AI Scientist, has been an outspoken critic of autoregressive LLMs. His “unpopular opinion” is that next-word prediction is an inadequate path toward real intelligence, and that autoregressive models are ultimately doomed. According to LeCun, such models cannot reliably be made factual, safe, or controllable. He frames the problem probabilistically: with an error rate e—the probability that any generated token falls outside the set of correct answers—the likelihood that an entire answer of length n remains correct is given by
P(correct) = (1 – e)ⁿ
This probability diverges exponentially as sequences grow longer, making the problem fundamentally unfixable in his view. Instead, LeCun advocates for alternative architectures grounded in world models, structured representations, and self-supervised predictive learning beyond text. While large language models have shown remarkable versatility despite these flaws, his critique underscores an ongoing debate: will scaling autoregressive systems eventually hit a ceiling before reaching human-level reasoning? But it is important to remark that, despite appealing, there is not enough research in this direction and many aspects can be questioned. For example, attention span is a problem that has been tackled with remarkable success at a fast pace.
Final remarks
To conclude this overview of trustworthy AI, I’ll offer a futuristic bet grounded in our discussion. LLMs are being deployed across a wide range of applications, which in turn accelerates their progress. Yet in the pursuit of more general intelligence, transformer-based systems still stumble on certain cognitive tasks, many of which are trivial for humans but surprisingly hard for LLMs (e.g., the first-token bias; check out our CloudWalk post regarding this topic). Some problems may not be solvable with language models alone. From a human perspective, language is grounded in world models: it’s a distributed function of the brain, tightly coupled to sensorimotor systems and higher-order cognitive processes. My bet, therefore, is on world-model approaches inspired by the brain and mind, new architectures that ground and integrate knowledge, to chart the path toward truly intelligent systems. This doesn’t mean LLMs won’t remain valuable; they already excel in many domains, especially when combined into modular systems that tackle specific tasks. But it’s unlikely that LLMs by themselves will lead to general intelligence.
References
Anthropic. (n.d.). anthropic-retrieval-demo [GitHub repository]. GitHub. Retrieved September 8, 2025, from https://github.com/anthropics/anthropic-retrieval-demo
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N. L., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Tamkin, A., Nguyen, K., McLean, B., … Olah, C. (2023, October 4). Towards monosemanticity: Decomposing language models with dictionary learning. Anthropic. https://transformer-circuits.pub/2023/monosemantic-features/
Chen, Y., Yan, L., Sun, W., Ma, X., Zhang, Y., Wang, S., Yin, D., Yang, Y., & Mao, J. (2025). Improving retrieval-augmented generation through multi-agent reinforcement learning. arXiv. https://doi.org/10.48550/arXiv.2501.15228
Chlon, L., Karim, A., & Chlon, M. (2025, September 14). Predictable compression failures: Why language models actually hallucinate [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2509.11208
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R. O., & Larson, J. (2024). From local to global: A graph RAG approach to query-focused summarization. arXiv. https://doi.org/10.48550/arXiv.2404.16130
Fan, W., Ding, Y., Ning, L., Wang, S., Li, H., Yin, D., Chua, T.-S., & Li, Q. (2024). A survey on RAG meeting LLMs: Towards retrieval-augmented large language models. arXiv. https://doi.org/10.48550/arXiv.2405.06211
Farquhar, S., Kossen, J., Kuhn, L., et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature, 630, 625–630. https://doi.org/10.1038/s41586-024-07421-0
He, X., Tian, Y., Sun, Y., Chawla, N. V., Laurent, T., LeCun, Y., Bresson, X., & Hooi, B. (2024). G-Retriever: Retrieval-augmented generation for textual graph understanding and question answering. arXiv. https://doi.org/10.48550/arXiv.2402.07630
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Lin (Eds.), Advances in Neural Information Processing Systems (Vol. 33, pp. 9459–9474). Curran Associates, Inc. https://doi.org/10.48550/arXiv.2005.11401
Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query rewriting for retrieval-augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023). https://doi.org/10.48550/arXiv.2305.14283
Ram, O., Levine, Y., Dalmedigos, I., Muhlgay, D., Shashua, A., Leyton-Brown, K., & Shoham, Y. (2023). In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics. https://doi.org/10.48550/arXiv.2302.00083
Udandarao, V., Prabhu, A., Ghosh, A., Sharma, Y., Torr, P., Bibi, A., Albanie, S., & Bethge, M. (2024). No “zero-shot” without exponential data: Pretraining concept frequency determines multimodal model performance. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS 2024). https://openreview.net/forum?id=9VbGjXLzig


Explore our content
Get to know and learn more about Cloudwalk below.

![[Paper-club sessions] LIMO: Less is More for Reasoning](https://cdn.prod.website-files.com/6654b3697a9d140e0ca14e14/68c29fab9171604aaae334a4_ChatGPT%20Image%2011%20de%20set.%20de%202025.png)

.png)
